Introduction : Bienvenue dans l’Ère de l’Indexation par l’IA
En 2025, la manière dont l’information est découverte et consommée a radicalement changé. Nous ne nous contentons plus de “googler” ; nous demandons désormais à des intelligences artificielles comme ChatGPT. Mais pour que ChatGPT puisse répondre avec des informations fraîches et précises, il doit lire le web. C’est là qu’interviennent les crawlers de ChatGPT.
Souvent perçus comme des entités mystérieuses, ces robots d’exploration sont les yeux et les oreilles des modèles de langage. Ce guide vous dévoile tout ce qu’il faut savoir sur ces outils : leur fonctionnement, comment les optimiser pour votre référencement (SEO/GEO), et comment contrôler leur accès à votre contenu.
Qu’est-ce qu’un Crawler dans l’Univers ChatGPT ?
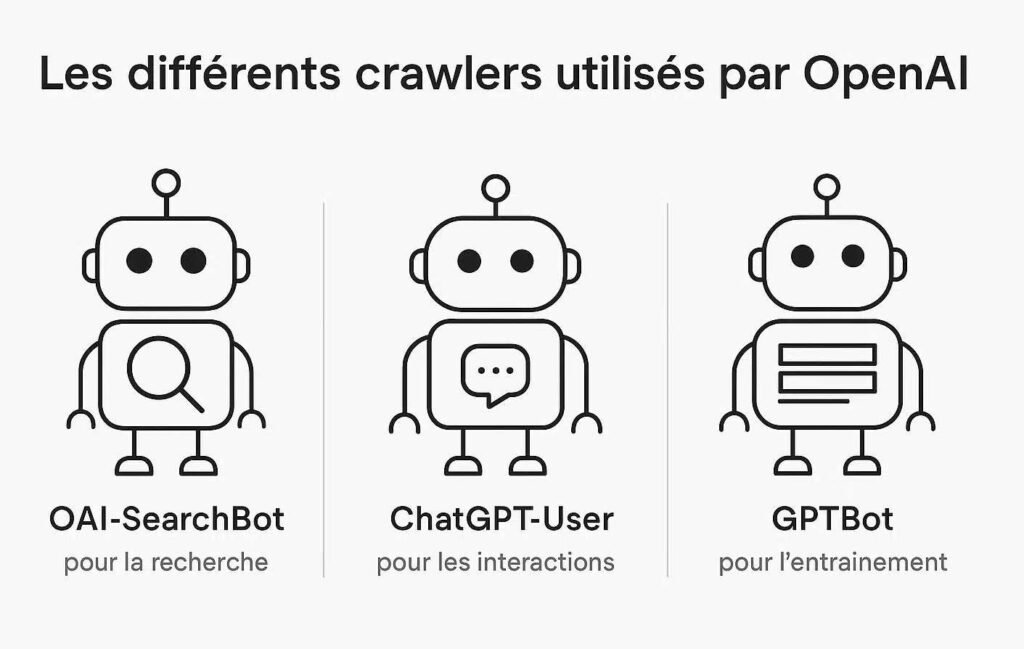
Un crawler, ou robot d’exploration, est un programme automatisé qui parcourt le World Wide Web pour découvrir et analyser des pages. Dans le contexte de ChatGPT, OpenAI utilise plusieurs agents utilisateurs (user-agents) distincts, chacun ayant une mission spécifique.
Il est crucial de ne pas les confondre. Voici les principaux crawlers à connaître :
| Nom du Bot | Rôle Principal | Impact pour le Webmaster |
|---|---|---|
| GPTBot | Explore le web pour collecter des données publiques. Ces données servent à entraîner et améliorer les modèles de langage (LLM) comme GPT-5. | Influence la connaissance “générale” du modèle. |
| OAI-SearchBot | Permet à ChatGPT d’effectuer des recherches en temps réel (Browse Mode) pour répondre à une requête spécifique en citant ses sources. | Essentiel pour apparaître dans les réponses sourcées et générer du trafic. |
| ChatGPT-User | Agent utilisé lorsque ChatGPT agit comme un agent autonome pour accomplir des tâches (ex: interagir avec un plugin ou un site pour le compte de l’utilisateur). | Interaction dynamique avec les services en ligne. |
Comprendre cette distinction est la première étape pour élaborer une stratégie de contenu efficace. Si vous souhaitez que votre site soit cité comme source fiable, c’est OAI-SearchBot qu’il faut laisser entrer. Si vous vous inquiétez de l’utilisation de votre contenu pour l’entraînement, c’est GPTBot qu’il faut surveiller.
“GPTBot is OpenAI’s official web crawler, designed to scan public web pages and feed information to train AI models, such as ChatGPT. It’s sort of Googlebot, but instead of building a search index, it helps LLMs ‘learn’ from online content.”
Le Mécanisme d’Exploration : Comment ChatGPT “Voit” Votre Site ?
Lorsqu’un utilisateur active la browsing mode (navigation) dans ChatGPT, le modèle ne consulte pas une base de données figée. Il suit un processus dynamique en plusieurs étapes pour construire sa réponse .
- Analyse de la Requête : Le système détermine d’abord le type d’information nécessaire (définition, tutoriel, comparaison de produits, etc.).
- Recherche et Récupération d’URLs : OAI-SearchBot est activé pour identifier les pages les plus pertinentes. Il privilégie les sites à haute autorité, les pages fréquemment mises à jour, et celles ayant une structure claire.
- Filtrage de Pertinence : Le bot analyse le contenu. Il exclut automatiquement les pages au contenu pauvre, trompeur, excessivement promotionnel, ou caché derrière des murs de paie.
- Extraction de la Preuve : Ce n’est pas toute la page qui est lue, mais des “blocs de contenu” spécifiques. ChatGPT excelle à identifier et extraire :
- Des listes à puces.
- Des tableaux comparatifs.
- Des définitions courtes et précises.
- Des instructions pas-à-pas.
- Synthèse Générative : Enfin, l’IA synthétise ces informations provenant de multiples sources pour formuler une réponse cohérente, citant souvent ses sources pour plus de transparence.
Cette méthode signifie que votre site n’a pas besoin d’être “premier sur Google” pour être cité par ChatGPT, mais il doit être parfaitement structuré pour que ses “blocs d’information” soient facilement extractibles .
Optimiser son Site pour les Crawlers d’IA : Le Guide Pratique
Pour être la référence que ChatGPT cite, il ne suffit plus d’optimiser pour des mots-clés. Il faut optimiser pour l’extraction. Voici comment procéder.
1. Structurez votre Contenu en “Blocs Extractibles”
ChatGPT scanne votre page à la recherche d’informations qu’il peut facilement isoler et reformuler.
- Utilisez des listes à puces (
<ul>,<ol>) et des tableaux (<table>) pour les données comparatives. Les bots d’IA adorent ces formats. - Rédigez des définitions concises. Si votre article explique un concept, mettez une définition claire en 2-3 phrases en haut de page, idéalement dans un encadré ou un paragraphe bien distinct.
- Adoptez des titres de section explicites (
<h2>,<h3>). Évitez les titres trop créatifs ou vagues. “Comment installer X en 5 étapes” est bien plus efficace qu'”À la découverte de X”.
2. Devenez une “Entité” Clairement Identifiable
L’IA cherche à comprendre qui vous êtes et si vous êtes digne de confiance.
- Marquage Schema.org : Implémentez des données structurées (Person, Organization, Article, FAQPage). Cela aide le bot à comprendre le contexte de votre contenu.
- Page “À propos” substantielle : Rédigez une page “À propos” détaillée, présentant l’histoire de l’entreprise, son équipe, et ses valeurs.
- Cohérence des noms : Utilisez le même nom de marque partout sur le web. Si vous êtes “Ma Super Entreprise”, ne devenez pas “Super Entreprise SAS” ailleurs.
3. Prouvez par l’Exemple et la Donnée
ChatGPT est un modèle probabiliste. Pour qu’il vous cite comme source fiable, il a besoin de “preuves” dans votre texte.
- Citez des études et des statistiques : “Selon une étude de l’INSEE de 2024…” est un aimant à citations pour l’IA.
- Fournissez des exemples concrets : Ne vous contentez pas de théorie. Des études de cas et des exemples pratiques augmentent la valeur perçue de votre contenu .
4. Maîtrisez l’Accès via le Fichier
robots.txt
Le fichier
robots.txt
est votre outil de contrôle. Vous pouvez autoriser ou interdire l’accès aux bots d’OpenAI.
- Pour autoriser OAI-SearchBot (et être cité) :
User-agent: OAI-SearchBot
Allow: /
Disallow: /privé/ # Vous pouvez toujours bloquer des dossiers spécifiques- Pour bloquer GPTBot (empêcher l’utilisation pour l’entraînement) :
User-agent: GPTBot
Disallow: /- Pour bloquer tous les bots OpenAI :
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /“Pour aider à garantir que vos contenus puissent être découverts, mis en évidence et cités, suivez ces lignes directrices. Assurez-vous de ne pas bloquer OAI-SearchBot.”
Cas d’Usage Inversé : Utiliser ChatGPT pour Faire du Scraping
Si les crawlers d’OpenAI lisent le web, la communauté technique a trouvé le moyen d’utiliser ChatGPT comme un assistant au scraping. Attention, nuance importante : ChatGPT ne peut pas scraper le web directement (il ne peut pas aller chercher une page en direct sans son module Browse). En revanche, il est un allié de taille pour écrire le code qui scrapera pour vous .
Le ChatGPT, Codeur en Chef
Imaginez que vous vouliez extraire les prix de livres sur une page. Au lieu d’écrire le code de zéro, vous demandez à ChatGPT :
“Write a Python script using BeautifulSoup to scrape the title and price of products from ‘https://exemple.com/produits’. The title is in an
<h4>tag inside adivwith class ‘product-card’, and the price is in aspanwith class ‘price’.”
ChatGPT vous générera un script fonctionnel en quelques secondes, gérant les requêtes HTTP, le parsing HTML et l’export CSV .
Prompt d’exemple pour générer un scraper :
Write a web scraper using Python and BeautifulSoup.
Target: https://sandbox.oxylabs.io/products
Goal: Scrape product titles and prices.
CSS selectors:
1. Title: h4.product-title
2. Price: div.price-wrapper span
Output: Save in a CSV file.Les Limites de l’Approche “ChatGPT + Scraping”
Si ChatGPT est un excellent générateur de code, il ne fait pas tout.
- Il ne contourne pas les protections : Sites avec JavaScript lourd, anti-bots, CAPTCHA… ChatGPT ne peut pas gérer cela. Il faudra des outils spécialisés comme Selenium ou des APIs de scraping .
- Code à vérifier : Le code généré peut contenir des bugs ou ne pas être optimal. Une relecture humaine est indispensable.
Avis d’expert :
“Utiliser ChatGPT pour le web scraping, c’est comme avoir un stagiaire surdoué : il écrit le code rapidement, mais il faut toujours vérifier son travail et il ne peut pas gérer les clients mécontents (les anti-bots).” — Adapté de l’analyse de Scrapeless .
Tableau Récapitulatif des Stratégies
Pour vous aider à y voir plus clair, voici un tableau synthétisant les bonnes pratiques :
| Objectif | Action à Entreprendre | Crawler Concerné |
|---|---|---|
| Être cité comme source dans les réponses | Optimiser le contenu (listes, définitions), autoriser OAI-SearchBot. | OAI-SearchBot |
| Empêcher l’utilisation de mon contenu pour l’entraînement | Bloquer GPTBot dans
robots.txt
. | GPTBot |
| Automatiser la collecte de données concurrentielles | Utiliser ChatGPT pour générer des scripts Python (requests, BS4). | N/A (vous êtes le crawler) |
| Analyser les tendances des réponses IA | Utiliser des APIs spécialisées (LLM Chat Scraper) pour surveiller les mentions de marque. | APIs tierces |
| Améliorer le référencement naturel (SEO) traditionnel | Continuer les bonnes pratiques SEO (backlinks, vitesse, mobile-friendly). | Googlebot (et autres) |
Conclusion : Vers une Coexistence Intelligente
Les crawlers de ChatGPT, comme GPTBot et OAI-SearchBot, ne sont pas une mode passagère. Ils redéfinissent l’architecture de l’information en ligne. En tant que créateurs de contenu ou propriétaires de sites, nous avons désormais le pouvoir de choisir notre niveau d’interaction avec ces nouveaux moteurs de découverte.
Bloquer ces bots est un droit, mais c’est peut-être aussi une occasion manquée d’atteindre un public qui ne “cherche” plus, mais qui “demande”. À l’inverse, les accueillir demande une adaptation de notre manière d’écrire et de structurer le savoir.
L’avenir du web ne sera pas opposé à l’IA, mais en symbiose avec elle. En comprenant et en respectant les règles de ces nouveaux explorateurs numériques, nous pouvons nous assurer que nos voix continueront d’être entendues dans le grand concert de l’intelligence artificielle.